Mean rolling correlation of XLF constituents
I follow Quantocracy on Twitter, and I found Rolling mean correlation in the tidyverse by Robot Wealth. They say to let them know if you’d approach it differently. I would, so I thought it would be interesting to replicate the analysis using tools I’m familiar with: xts and TTR.
The xts package is an extension of the very excellent zoo package. zoo objects are for ordered observations. Underneath, they are a matrix that can be ordered by anything: numbers, letters, dates, times, and more. xts objects are a special type of zoo object that can only be ordered by a date-time. They are the most common data structure used for working with financial time series, and are used in many of the major time series packages. You can find more details about xts objects in the xts vignette.
I like xts so much, I took over as maintainer when Jeff Ryan started working at a hedge fund that didn’t let him continue open source work.
TTR is the first R package I wrote, all the way back in 2007, before R was cool! TTR has a collection of over 50 technical indicators for creating technical trading rules. The package also provides fast implementations of common rolling-window functions, and several volatility calculations. We’re going to use its ROC() (rate-of-change) function to calculate returns.
Okay, now on to the code!
First, you need to download the data set. I’ve saved a copy of the data that was provided in the Robot Wealth post. You can download it here. The Robot Wealth post used the tidyverse, so data is saved in the preferred tidyverse data structure, a tibble (it’s like a data frame).
Then we need to load() the data into our R session. This creates an object named prices_xlf. The data has 10 columns: ticker, date, open, high, low,close, volume, dividends, closeunadj, inSPX. We’re only going to use the date, ticker, and close columns.
Now we need to convert the prices_xlf tibble into an xts object. There’s no standard way to do this, because tibbles don’t have a pre-defined structure for financial time series. We can ‘read’ and convert the data from a tibble into a zoo object using read.zoo(). We’re using read.zoo() because there isn’t a read.xts() function, and we can easily convert from zoo to xts using as.xts().
load("xlfprices.RData")
library(xts)
x <- read.zoo(prices_xlf[, c("date", "ticker", "close")],
index.column = "date", split = "ticker")
## Warning in zoo(rval4[[i]], ix[[i]]):
## some methods for "zoo" objects do not work
## if the index entries in 'order.by' are not unique
## Error in merge.zoo(AFL = structure(c(30.54, 29.74, 29.475, 29.66, 29.95, :
## series cannot be merged with non-unique index entries in a series
We pass prices_xlf to read.zoo(), but only with the columns we need for our analysis. The index.column argument tells read.zoo() which column in the data has the ordered index. The split argument allows us to reshape the data from a long format into a wide format, where each ticker is in its own column. This is the standard format for xts objects, because it makes working with financial time series a lot easier.
Now to run the code. Hmm… it throws an error. The error means there are duplicate dates for at least one of the tickers in the prices_xlf object. Depending on how many duplicates there are, this may or may not bias the results, but we should remove them anyway so the analysis is correct. This is another benefit of xts/zoo objects.
Let’s take a look at the duplicates, and then remove them.
# find the duplicates
duplicate_rows <- duplicated(prices_xlf)
# view the duplicates
head(prices_xlf[duplicate_rows, ])
## ticker date open high low close volume dividends
## 61839 CB 2016-01-29 110.18 113.17 110.00 113.07 4205800 0
## 61904 CB 2016-01-28 108.55 109.84 108.42 109.52 3313800 0
## 61969 CB 2016-01-27 108.15 109.91 107.07 108.10 3433200 0
## 62034 CB 2016-01-26 108.51 109.76 108.00 108.58 2669500 0
## 62099 CB 2016-01-25 109.95 109.99 107.82 108.00 2985000 0
## 62164 CB 2016-01-22 109.70 110.97 109.48 110.04 2296000 0
## closeunadj inSPX
## 61839 113.07 TRUE
## 61904 109.52 TRUE
## 61969 108.10 TRUE
## 62034 108.58 TRUE
## 62099 108.00 TRUE
## 62164 110.04 TRUE
# remove the duplicates
prices <- unique(prices_xlf)
The duplicated() function returns a logical (true/false) vector as long as the number of rows in your data. Any row it finds that matches a previous row in the data will be TRUE in the vector. Note that only the duplicated rows are TRUE. The first rows found will be FALSE. Subsetting prices_xlf by the duplicated() result will return the rows that exist somewhere in previous rows in the data.
You can probably guess what the unique() function does. It removes all the duplicated rows. Now that we removed the duplicates, we can try the read.zoo() call again.
# reshape data into wide format
x <- read.zoo(prices[,c("date", "ticker", "close")],
index.column = "date", split = "ticker")
Great, that worked! Now we will convert from zoo to xts, because xts gives us a handful of fancy features in addition to all the awesomeness that comes with zoo. We’re not going to use those fancy features in this post, but I promise, they’re fancy.
Next we will calculate returns using the ROC() (rate-of-change) function from the TTR package.
# convert from zoo to xts
x <- as.xts(x)
# calculate returns
library(TTR)
returns <- ROC(x) # log returns
returns <- ROC(x, type = "discrete") # arithmetic returns
The single call to as.xts() is all you need to convert from zoo to xts. ROC() calculates log returns by default, but it will calculate discrete (or arithmetic) returns if you set type = "discrete". We’re going to use discrete returns to keep things consistent with the Robot Wealth post.
Next we will create a function to calculate the mean pairwise correlation for each pair of columns in our xts object. We can get all the pairwise correlations from the correlation matrix.
Once we calculate the correlation matrix, we can calculate the mean correlation by taking the mean of the entire matrix. You may be thinking that this will take the mean of each correlation value two times (once for the upper triangle of the matrix, and another time for the lower triangle). But the values in both triangles are the same, because the matrix is symmetric about the diagonal. So this will not affect the mean calculation.
mean_cor <-
function(returns)
{
# calculate the correlation matrix
cor_matrix <- cor(returns, use = "pairwise.complete")
# set the diagonal to NA (may not be necessary)
diag(cor_matrix) <- NA
# calculate the mean correlation, removing the NA
mean(cor_matrix, na.rm = TRUE)
}
Since our data are in a wide format, calculating the correlation matrix is takes a single call to the cor() function that comes with your R installation.
Then we set the diagonal of the matrix to NA because they are all equal to 1. That may not be necessary, but it could bias the results, and I’m not ready to spend time thinking about it. :)
Finally, we take the mean of the entire correlation matrix.
Now that we have a handy-dandy mean_cor() function to calculate the mean pairwise correlations, we can call the function on a rolling, 60-day period. We can do this with the rollapply() function from the zoo package.
# calculate the rolling mean correlation over 60 periods
cors <- rollapply(returns, 60, mean_cor, by.column = FALSE, align = "right")
We set align = "right" in order ‘right-align’ the result. That means the timestamp for each rolling window will be the right-most (or last/largest) value in the window. This is important because we do not know the value for the rolling period until the end of the window. We would severely bias our results if we used the ’left’ (first) or ‘center’ (middle) timestamp for our window calculation.
We also need to set by.column = FALSE. Otherwise, the rollapply() function will run the function on each column of the xts object individually. And it doesn’t make sense to try and calculation the correlation matrix of a single series.
Now, let’s plot our rolling 60-day correlations. We only need to call the plot() function to get a quick look.
plot(cors, main = "Rolling mean XLF correlations")
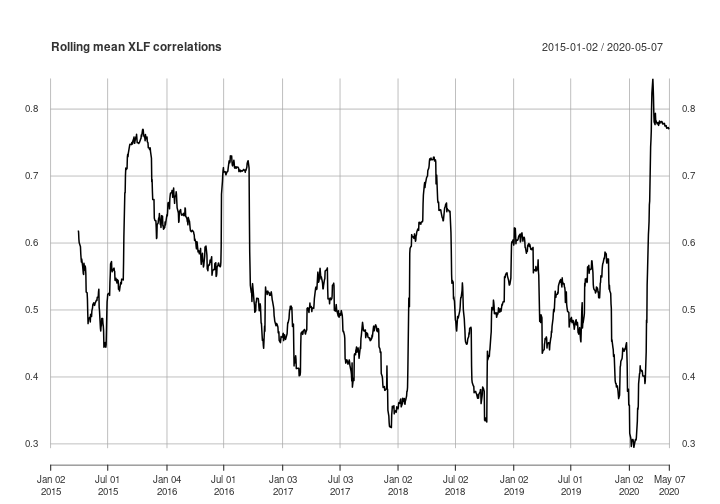
The main thing I like about my approach is how few lines of code it takes. The most complicated piece is the mean_cor() function, but even that is fairly straightforward.
You can do similar analysis using this same pattern. You need to create another function to calculate the metric, but everything else will be the same.
Like the Robot Wealth version, you can easily do this entire analysis in memory. You don’t have to bother with chunking it up into smaller pieces and piecing it back together.
One difference is that the data in their version is just under 3 million (!) rows, and 6 columns (~18 million data points). This version is 1346 rows and 65 columns (less than 100,000 data points). So you could quickly do the analysis in memory this way on ETFs or indexes with many more constituents (e.g. the Russell 3000). I’ve worked on xts data sets with ~1 billion rows of tick data on my machine with 32GB of RAM.
If you love using my open-source work (e.g. quantmod, TTR, xts, IBrokers, microbenchmark, blotter, quantstrat, etc.), you can give back by sponsoring me on GitHub. I truly appreciate anything you’re willing and able to give!